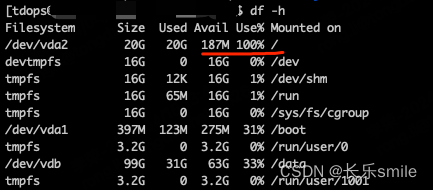
Hugging Face的Pipeline是一个现成的解决方案,它将一系列预训练模型组合在一起,以完成特定的任务。你可以将其视为一个“流水线”,它会依次将输入数据传递给多个模型,每个模型负责完成任务的一部分。
举个例子,假设你有一个文本分类任务,要求根据文章的内容将其分类为不同的类别(如科技、娱乐、体育等)。在这种情况下,你可能需要一个模型来提取文章的关键信息,另一个模型来根据这些信息进行分类。Pipeline会自动将这两个模型串联起来,形成一个完整的解决方案。
以下是Pipeline的基本步骤:
-
输入数据:首先,你需要提供一些输入数据,例如文章的文本内容。
-
数据预处理:Pipeline会自动对输入数据进行预处理,如分词、去除停用词等,使其适合后续模型的处理。
-
模型处理:接下来,数据会被传递给第一个模型。这个模型可能会负责提取文本中的关键信息,如实体名称、关键词等。
-
中间表示:第一阶段的模型输出会作为第二阶段模型的输入。这个中间表示通常是一种向量或张量,能够捕捉到原始数据中的重要特征。
-
最终模型:最后,数据会被传递给第二个模型(如分类器),它会根据前面模型的输出将数据分类为不同的类别。
-
结果输出:Pipeline会将最终的分类结果返回给你,这样你就可以根据需要使用这些分类信息了。
通过使用Pipeline,你可以轻松地搭建起复杂的机器学习任务,而无需自己编写所有代码。此外,Hugging Face还提供了许多预训练模型和预定义的Pipeline,让你可以快速开始各种NLP和计算机视觉任务。